With the phenomenal hit of generative AI applications with one of the most prominent being ChatGPT, there is a lot of interest and speculation in this field of artificial intelligence and deep learning. There are newer and better applications being developed by the likes of Google and Microsoft (most of you might be familiar) and other companies racing in this field, it can be of great use to learn the underlying architecture and the overall basic building blocks about the architectures that power ChatGPT: Transformers.
While OpenAI can be using modified versions of transformers along with reinforcement learning, getting to understand the basics of transformers can help one to gain a good understanding about the overall picture of generative AI applications and also aid readers in the process of discovering new innovations in the field. In this article, we can be mainly focusing on the working of transformers and the important equations that lead to self-attention and how encoder-decoder networks interact in order to generate text based on various prompts given by the user.
In the past before the discovery of transformers, sequence-to-sequence modeling was performed (slow) with networks such as LSTMs, GRUs and RNNs. While they do a good job in capturing the structure of a given text (looking at the past to determine the next set of words), training large volumes of text can be time consuming due to their nature of processing text sequentially. In addition to this, they often suffer from vanishing gradient problem when they encounter texts that are too long. As a result, they fail to capture important information from the past text that is too long and beyond their reach.
It was because of these limitations that there was a good amount of research for better architectures that resulted in state-of-the-art results in language modeling tasks such as text summarization, sentence classification and others. After the discovery of transformers, they revolutionized the natural language processing industry. However, their true potential was not yet realized beyond the NLP and deep learning community. It was with the invention of ChatGPT that a large number of people showed growing interest to learn about the underlying architectures and their functioning.
We will now take a look at a few blocks of code and understand the working of transformers along with a few examples to further gain intuition about the inner workings of the transformer model.
Note that this is a basic implementation of transformers with blocks that may not represent the true model used by OpenAI. However, it can give a good idea and a general understanding of their working in detail.
We can divide the coding into a few sections to help us better understand the dependencies between various components that make up a transformer in detail.
This is one of the important components in a transformer. In this method, we define a set of weights namely k, q and v which stand for key, query and value. These are multiplied separately with the text embedding and multiple such layers are formed to give rise to attention. In order words, these variables compute the attention that must be captured for all the previous words in a sentence based on the present word. In this way, we can get to know the actual attention of various words previous to the present word to determine the final output. In order to give a better understanding, I will give a good example to demonstrate this concept. Let us now consider the following example sentence.
“It is generally hot when it is sunny.”
In this sentence, if we were to remove the word “sunny” and ask the transformer model to make prediction of the words that could be present in that space, it would mostly give attention to word “hot” and “when” to make a prediction about the word “sunny”. Therefore, the vectors that we have considered above (k, q, v) are used to determine the total attention to be given to all the previous words based on the present word. In this example, once it pays attention to “hot” and “when”, it will most probably be able to identify that the present word is “sunny”. We will now define this as a class with the necessary variables which could be used to determine the attention.

In this code, the variable d_model stands for the dimensionality of the embedding we use to convert text into vectors. For this, we can use either word2vec or glove vectors to covert it into a multidimensional
vector. The variable num_heads is used to determine the number of attention heads needed for the task. The head_dim ensures that equal number of dimensions are assigned to each of the
attention head.
We initialize the weight vectors W_Q , W_K , and W_V that are used to compute the attention needed for each of the set of words. There is reshaping of these values such that
it is possible to multiply them and fill the attention scores. Finally, a softmax layer is considered to determine the probabilities of each of the words based on the attention to a list of previous words. The
output is represented as a linear unit.
Below is the implementation of the transformer block that highlights various normalization procedures followed to form a complete transform block.
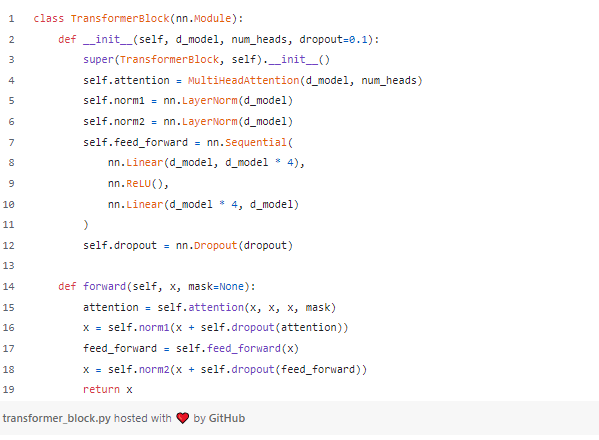
As we have previously defined the MultiHeadAttention class in the previous code cell, we use it in TransformerBlock and get normalization layers and feed forward neural networks. Finally,
a dropout layer is used to ensure that overfitting could be reduced.
In the forward method, attention is used with adequate masking with a few other layers such as normalization and dropout added. The final model is returned after performing these steps.
After performing and adding each of these methods, we call the subsequent ones depending on the operation performed in a transformer.
As we have looked at the basic building blocks of transformer models, we got a good undestanding about the working of them in detail. Multi-headed attention is an important component in a transformer model as it is able to determine the total attention that must be placed on various set of works in order to make predictions for the next set of words. Thanks for taking the time to read this article.
Below are the ways where you could contact me or take a look at my work.
GitHub: suhasmaddali (Suhas Maddali ) (github.com)
YouTube: https://www.youtube.com/channel/UCymdyoyJBC_i7QVfbrIs-4Q
LinkedIn: (1) Suhas Maddali, Northeastern University, Data Science | LinkedIn
Medium: Suhas Maddali — Medium
