
Meta’s release of Llama 3 in July 2024 has significantly impacted the landscape of large language models (LLMs). Unlike other open LLMs, Meta not only shared the model weights but also published a comprehensive paper detailing their training recipe. This generosity is rare and provides a lot of valuable insights. Even if you’re a user who doesn’t train LLMs from scratch, it still offers useful lessons.
At its core, Llama 3 employs a straightforward neural net architecture, but its strength lies in meticulous data curation and iterative training. This underscores the effectiveness of the good old Transformer architecture and highlights the importance of training data.
In this post, I’ll share key takeaways from the Llama 3 paper, highlighting three practical aspects: data curation, post-training, and evaluation.
Data curation, which involves gathering, organizing, and refining data to ensure its quality and relevance for training machine learning models, is a cornerstone of Llama 3’s development. The process is divided into two phases: pre-training and post-training. In the pre-training phase, Meta’s team significantly reworked the data curation process to collect high-quality data from the web.
In the post-training phase, Meta’s team tackled the challenge of data quality by primarily relying on synthetic data.
Llama 3’s development was not about achieving perfection on the first try. Instead, they embraced an iterative, multi-stage approach, refining components progressively. The team was open to ad-hoc solutions for specific challenges, undergoing six rounds of reward modeling, SFT, and DPO. They crafted many model variants from experiments using various data and hyperparameters and averaged their weights at the end. This training pipeline is fairly complex compared to the industry standard.
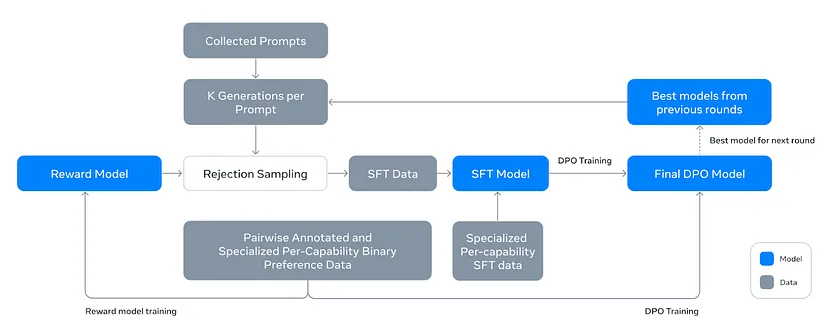 Llama 3’s post-training pipeline
Llama 3’s post-training pipeline
With a refined model through iterative post-training, the next crucial step was to rigorously evaluate Llama 3’s capabilities and limitations. Beyond standard benchmarks, they explored the model’s sensitivity to input variations (see the image below), which is crucial for practitioners as minor differences in prompts can lead to unexpected results. They also tackled data contamination issues, ensuring the model hadn’t been inadvertently trained on benchmark data, which can skew performance evaluations.
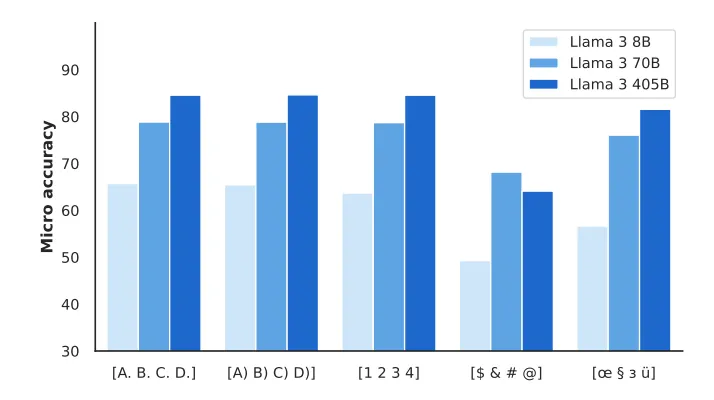 Robustness to different label variants in the MMLU benchmark
Robustness to different label variants in the MMLU benchmark
